Chapter 11 Text Data
In this section we give an introduction to strings and string operations, how to extracting and manipulating string objects, and an introduction to general search methods.
We have focus on character objects in particular because a lot of the “messy” data comes in character form. For example, web pages can be scraped, email can be analyzed for network properties and survey responses must be processed and compared. Even if you only care about numbers, it helps to be able to extract them from text and manipulate them easily.
In general we will try to stick to the following distinction. However, many people will use the term “character” and “string” interchangeably.
- Character: a symbol in a written language, specifically what you can enter at a keyboard: letters, numerals, punctuation, space, newlines, etc.
'L', 'i', 'n', 'c', 'o', 'l', 'n'- String: a sequence of characters bound together
'Lincoln'Note: R does not have a separate type for characters and strings
## [1] "character"## [1] "character"11.1 Making Strings
Use single or double quotes to construct a string, but in general its recommeded to use double quotes. This is because the R console showcases character strings in double quotes regardless of how the string was created, and sometimes we might have single or double quotes in the string itself.
## [1] "Lincoln"## [1] "Lincoln"## [1] "Abraham Lincoln's Hat"## [1] "As Lincoln never said, 'Four score and seven beers ago'"## [1] "As Lincoln never said, \"Four score and seven beers ago\""The space, " " is a character; so are multiple spaces " " and the empty string, "".
Some characters are special, so we have “escape characters” to specify them in strings.
- quotes within strings: \"
- tab: \t
- new line \n and carriage return \r – use the former rather than the latter when possible.
Recall that strings (or character objects) are one of the atomic data types, like numeric or logical. Thus strings can go into scalars, vectors, arrays, lists, or be the type of a column in a data frame. We can use the nchar() to get the length of a single string.
## [1] 1## [1] 3## [1] 7## [1] 23## [1] 7 9 5We can use print() to display the string, and cat() is used to write the string directly to the console. If you’re debugging, message() is R’s preferred syntax.
## [1] "Abraham Lincoln"## Abraham Lincoln## Fillmore Pierce Buchanan Davis Johnson## FillmorePierceBuchananDavisJohnson11.2 Substring Operations
Substring: a smaller string from the big string, but still a string in its own right.
A string is not a vector or a list, so we cannot use subscripts like [[ ]] or [ ] to extract substrings; we use substr() instead.
## [1] "as Bo"We can also use substr to replace elements:
## [1] "Christmas Bogus"The function substr() can also be used for vectors.
substr() vectorizes over all its arguments:
## [1] "Fillmore" "Pierce" "Buchanan" "Davis" "Johnson"## [1] "Fi" "Pi" "Bu" "Da" "Jo"## [1] "re" "ce" "an" "is" "on"## [1] "" "" "" "" ""## [1] "r" "" "a" "" "n"11.3 Dividing Strings into Vectors
strsplit() divides a string according to key characters, by splitting each element of the character vector x at appearances of the pattern split.
## [[1]]
## [1] "parsley" " sage" " rosemary" " thyme"## [[1]]
## [1] "parsley" "sage" "rosemary" "thyme"Pattern is recycled over elements of the input vector:
## [[1]]
## [1] "parsley" "sage" "rosemary" "thyme"
##
## [[2]]
## [1] "Garfunkel" "Oates"
##
## [[3]]
## [1] "Clement" "McKenzie"Note that it outputs a list of character vectors.
11.4 Converting Objects into Strings
Explicitly converting one variable type to another is called casting. Notice that the number “7.2e12” is printed as supplied, but “7.2e5” is not. This is because if a number is exceeding large, small, or close to zero, then R will by default use scientific notation for that number.
## [1] "7.2"## [1] "7.2e+12"## [1] "7.2" "7.2e+12"## [1] "720000"11.5 Versatility of the paste() Function
The paste() function is very flexible. With one vector argument, works like as.character().
## [1] "41" "42" "43" "44" "45"With 2 or more vector arguments, it combines them with recycling.
## [1] "Fillmore 41" "Pierce 42" "Buchanan 43" "Davis 44" "Johnson 45"## [1] "Fillmore R" "Pierce D" "Buchanan R" "Davis D" "Johnson R"## [1] "Fillmore ( R 41 )" "Pierce ( D 42 )" "Buchanan ( R 43 )"
## [4] "Davis ( D 44 )" "Johnson ( R 45 )"We can changing the separator between pasted-together terms.
## [1] "Fillmore_ (_41_)" "Pierce_ (_42_)" "Buchanan_ (_43_)" "Davis_ (_44_)"
## [5] "Johnson_ (_45_)"## [1] "Fillmore (41)" "Pierce (42)" "Buchanan (43)" "Davis (44)"
## [5] "Johnson (45)"We can also condense multiple strings together using the collapse argument.
## [1] "Fillmore (41); Pierce (42); Buchanan (43); Davis (44); Johnson (45)"Default value of collapse is NULL – that is, it won’t use it.
11.6 Substitution
The functions gsub() and sub() are used to searcch for a pattern, and then substitue the matches. The function gsub() finds and replaces all matches, and the sub() finds and replaces only the first match.
scarborough.fair <- "parsley, sage, rosemary, thyme"
gsub(", ", "-", scarborough.fair) # replace all matches ## [1] "parsley-sage-rosemary-thyme"## [1] "parsley-sage, rosemary, thyme"11.7 Text of Some Importance
Consider the following quote from Abraham Lincoln. Often times we will want to study or analyze a block of text. To
“If we shall suppose that American slavery is one of those offenses which, in the providence of God, must needs come, but which, having continued through His appointed time, He now wills to remove, and that He gives to both North and South this terrible war as the woe due to those by whom the offense came, shall we discern therein any departure from those divine attributes which the believers in a living God always ascribe to Him? Fondly do we hope, fervently do we pray, that this mighty scourge of war may speedily pass away. Yet, if God wills that it continue until all the wealth piled by the bondsman’s two hundred and fifty years of unrequited toil shall be sunk, and until every drop of blood drawn with the lash shall be paid by another drawn with the sword, as was said three thousand years ago, so still it must be said”the judgments of the Lord are true and righteous altogether."
We can read in the file with the following commands.
the_url <- "https://raw.githubusercontent.com/rpkgarcia/LearnRBook/main/data_sets/al1.txt"
al1 <- readLines(the_url, warn = FALSE)
# How many lines in the file
length(al1)## [1] 1## [1] "If we shall suppose that American slavery is one of those offenses which, in the providence of God, must needs come, but which, having continued through His appointed time, He now wills to remove, and that He gives to both North and South this terrible war as the woe due to those by whom the offense came, shall we discern therein any departure from those divine attributes which the believers in a living God always ascribe to Him? Fondly do we hope, fervently do we pray, that this mighty scourge of war may speedily pass away. Yet, if God wills that it continue until all the wealth piled by the bondsman’s two hundred and fifty years of unrequited toil shall be sunk, and until every drop of blood drawn with the lash shall be paid by another drawn with the sword, as was said three thousand years ago, so still it must be said “the judgments of the Lord are true and righteous altogether”."Lets create a new vector where each element is a portion of text seperated by a comman “,”.
## [1] "If we shall suppose that American slavery is one of those offenses which"
## [2] " in the providence of God"
## [3] " must needs come"
## [4] " but which"
## [5] " having continued through His appointed time"
## [6] " He now wills to remove"
## [7] " and that He gives to both North and South this terrible war as the woe due to those by whom the offense came"
## [8] " shall we discern therein any departure from those divine attributes which the believers in a living God always ascribe to Him? Fondly do we hope"
## [9] " fervently do we pray"
## [10] " that this mighty scourge of war may speedily pass away. Yet"
## [11] " if God wills that it continue until all the wealth piled by the bondsman’s two hundred and fifty years of unrequited toil shall be sunk"
## [12] " and until every drop of blood drawn with the lash shall be paid by another drawn with the sword"
## [13] " as was said three thousand years ago"
## [14] " so still it must be said “the judgments of the Lord are true and righteous altogether”."11.8 Search
We can search through text strings for certain patterns. Some particularly helpful functions for doing this are grep() and grepl(). The grep() function
Narrowing down entries: use grep() to find which strings have a matching search term
## [1] 2 8 11## [1] FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE FALSE
## [13] FALSE FALSE## [1] " in the providence of God"
## [2] " shall we discern therein any departure from those divine attributes which the believers in a living God always ascribe to Him? Fondly do we hope"
## [3] " if God wills that it continue until all the wealth piled by the bondsman’s two hundred and fifty years of unrequited toil shall be sunk"11.9 Vectorizing Text Functions
A lot of the text functions above can only search or use one pattern at a time. For example, consider a situation in which we want to find all occurrences of the letters “a”, “b”, and “c” for the presidents vector.
presidents <- c("Fillmore", "Pierce", "Buchanan", "Davis", "Johnson")
abc <- c("a", "b", "c")
grepl(abc, presidents)## Warning in grepl(abc, presidents): argument 'pattern' has length > 1 and only
## the first element will be used## [1] FALSE FALSE TRUE TRUE FALSEWe can only search for one pattern at a time. To make this search more versatile we either have to do multiple searches, use regular expressions (see Chapter 18), or use some of the *apply functions. We saw examples of how to vectorize functions we created in Section 9.9. We can use these same methods with built in functions in R. Lets consider the example above again, but this time we will use sapply(). Notice that we have several arguments that we are using for grepl(). If we want to apply a function to multiple elements in a vector but this function has several arguments that is not a problem with sapply(). The function sapply() has a ... argument which we learned about in Section 7.6. The extra arguments are passed on to the function call because of this ... argument.
## a b c
## [1,] FALSE FALSE FALSE
## [2,] FALSE FALSE TRUE
## [3,] TRUE FALSE TRUE
## [4,] TRUE FALSE FALSE
## [5,] FALSE FALSE FALSEEach row corresponds to an element in the vector presidents, and each column contains TRUE\FALSE values depending on if the particular letter was present for that row.
We can use any() and all() functions to determine if the any or all of the letters “a”, “b” and “c” are present in a presidents name, respectively. We can do this with the apply() function. The apply() function iterates over a matrix instead of a vector. This function has three key arguments: X- the matrix we are iterating over, MARGIN- indicates if we iterate over rows (1) or columns (2), and FUN- the function to apply to each row or column of X. For instance, if we want to see which president has any of the letters present, we can do this individually for each row.
## [1] FALSE## [1] TRUE## [1] TRUE## [1] TRUE## [1] FALSEThis is inefficient, messy, and takes up space in our code. To instead, we can apply the any function to each row of our matrix. This returns the same values as above.
## [1] FALSE TRUE TRUE TRUE FALSESimilarly, for the all() function we can check if the presidents have the letters “a”, “b”, AND “c”.
## [1] FALSE FALSE FALSE FALSE FALSE11.10 Regular Expressions
We will cover regular expressions more thoroughly in Chapter 18, however, there are some important notes we should mention now. Most of the functions we discussed are not searching for simple strings of text, instead they are searching for something called “regular expressions”. These are strings of text where some symbols and characters have special meanings. The symbols that have special meanings are: . | ( ) [ { ^ $ * + ?. We call these metacharacters, and they are not treated like normal characters. For example, the “.” charcter is treated as a “any” character. If we try to use grep(), grepl(), gsub() or sub() with a “.” we will not get what we are expecting.
## [1] "PERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIODPERIOD"If we want to use one of the metacharacters without the special meaning we need to use an escape key \\.
## [1] "Hello neighborPERIOD"This escape key removes the special property, and works for all metacharacters.
11.11 Word Count Tables
Now lets break up the data set by spaces. We do this in hopes that it will separate each word as an element.
## [1] "If" "we" "shall" "suppose" "that" "American"We can now tabulate how often each word appears using the table() function. Then we can sort the frequencies in order using sort().
## al1.words
## the of and shall that to
## 9 6 5 4 4 4
## we be by those as do
## 4 3 3 3 2 2
## drawn God He in it must
## 2 2 2 2 2 2
## said this until war which, wills
## 2 2 2 2 2 2
## with years “the a ago, all
## 2 2 1 1 1 1
## altogether”. always American another any appointed
## 1 1 1 1 1 1
## are ascribe attributes away. believers blood
## 1 1 1 1 1 1
## bondsman’s both but came, come, continue
## 1 1 1 1 1 1
## continued departure discern divine drop due
## 1 1 1 1 1 1
## every fervently fifty Fondly from gives
## 1 1 1 1 1 1
## God, having Him? His hope, hundred
## 1 1 1 1 1 1
## if If is judgments lash living
## 1 1 1 1 1 1
## Lord may mighty needs North now
## 1 1 1 1 1 1
## offense offenses one paid pass piled
## 1 1 1 1 1 1
## pray, providence remove, righteous scourge slavery
## 1 1 1 1 1 1
## so South speedily still sunk, suppose
## 1 1 1 1 1 1
## sword, terrible therein thousand three through
## 1 1 1 1 1 1
## time, toil true two unrequited was
## 1 1 1 1 1 1
## wealth which whom woe Yet,
## 1 1 1 1 1Notice that punctuation using these methods is still present.
## He
## 2## <NA>
## NAIn addition, all our words and string subsets are case sensitive.
# What happens when we look for a word that is not in our
# word count table?
which(names(wc) == "That")## integer(0)## <NA>
## NA11.12 Wordcloud Package
Another package that is particularly useful for working with text data is the wordcloud package. This package extends the standard Base R plotting, and allows us to build word clouds. It uses the same general principals and features that we do with Base R.
Lets use the same Abraham Lincoln speech again. We will start by make everything lower case, and replace all whitepsace with a single space for consistency.
## Warning: package 'wordcloud' was built under R version 4.0.2## Loading required package: RColorBrewer## Warning: package 'RColorBrewer' was built under R version 4.0.2the_url <- "https://raw.githubusercontent.com/rpkgarcia/LearnRBook/main/data_sets/al1.txt"
al1 <- readLines(the_url, warn = FALSE)
# make everything lower case
al1 <- tolower(al1)
# see all individual words by spliting by white space
al1.words <- strsplit(al1, " ")
# Word count table
wc <- table(al1.words)
wc <- sort(wc, decreasing = T)
# Fixed issues from previous section
head(wc, 30)## al1.words
## the of and shall that to we be by those as
## 9 6 5 4 4 4 4 3 3 3 2
## do drawn god he if in it must said this until
## 2 2 2 2 2 2 2 2 2 2 2
## war which, wills with years “the a ago,
## 2 2 2 2 2 1 1 1## [1] "the" "of" "and" "shall" "that" "to"# Default plot (there is some randomness to how this plot
# is made, see Help file)
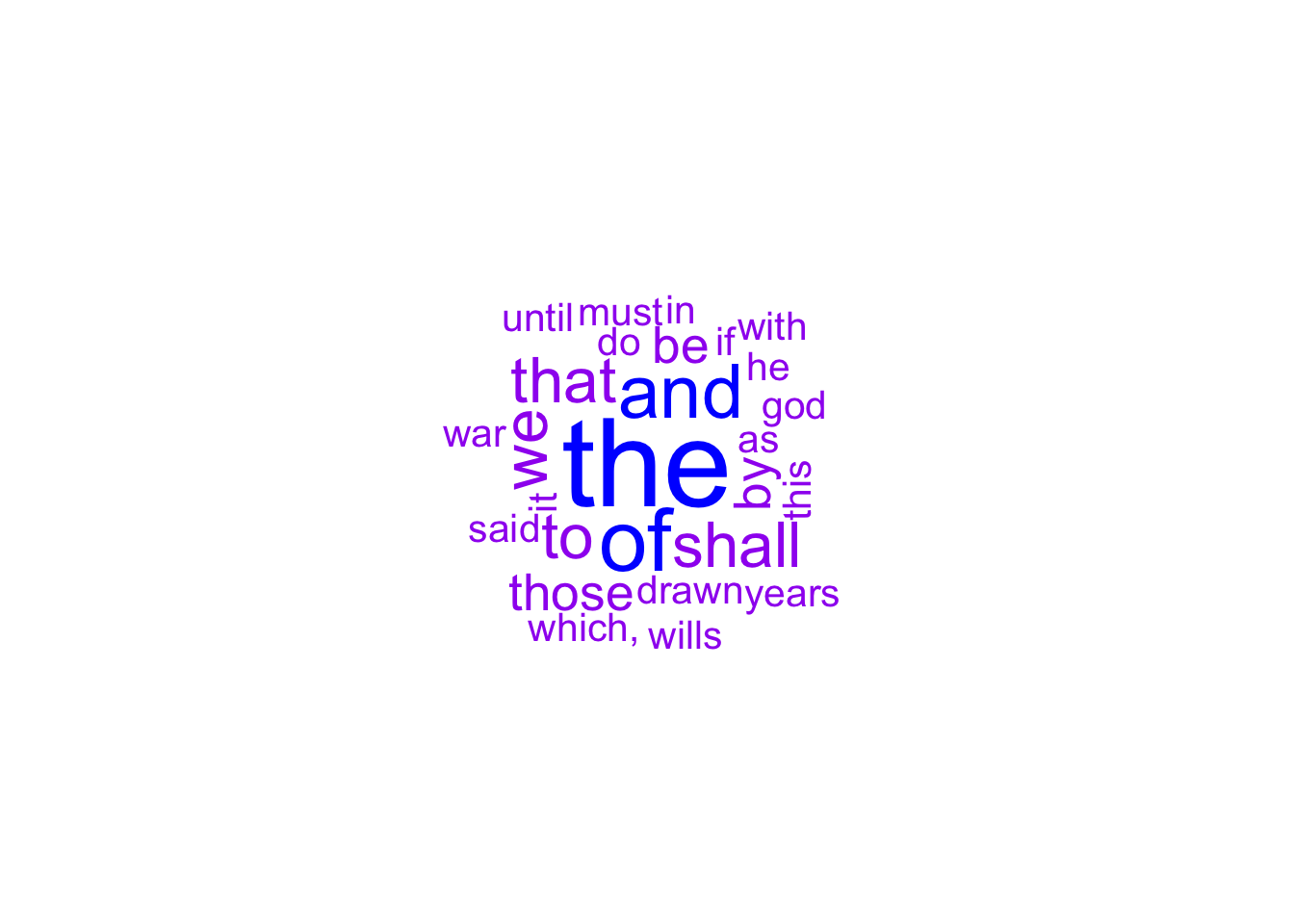
wordcloud(words = names(wc), freq = wc)
In a word cloud the freq argument controls how large the words will appear. In this case we let the size of the words be proportional to the frequency. There are a lot of extra features we can add to word clouds, feel free to explore them!
# Changing a few settings (Feel free to change more!! :)
# Have fun with it)
wordcloud(words = names(wc), freq = wc, min.freq = 2, random.order = F,
colors = c("purple", "blue"))